
ICML 2023
TL;DR. We propose a duality framework to solve the KPCA problem which leads to fast gradient-based algorithms, with extension to robust and sparse losses.
ICML 2023
TL;DR. We propose a duality framework to solve the KPCA problem which leads to fast gradient-based algorithms, with extension to robust and sparse losses.
The goal of this paper is to revisit Kernel Principal Component Analysis (KPCA) through dualization of a difference of convex functions.
This allows to naturally extend KPCA to multiple objective functions and leads to efficient gradient-based algorithms avoiding the expensive SVD of the Gram matrix.
Particularly, we consider objective functions that can be written as Moreau envelopes, demonstrating how to promote robustness and sparsity within the same framework.
The proposed method is evaluated on synthetic and real-world benchmarks, showing significant speedup in KPCA training time as well as highlighting the benefits in terms of robustness and sparsity.
Given: \(n\) datapoints \((x_i)_{i=1}^n \in \mathcal{X}^n\), feature map \(\phi \colon \mathcal{X} \to \mathcal{H}\) to a Hilbert space \(\mathcal{H}\).
Goal: find \(s\) directions in \(\mathcal{H}\) that maximize the variance under orthonormal conditions. The KPCA optimization problem is
\[\sup_{W \in \mathcal{S}_{\mathcal{H}}^s} \frac{1}{2} \|\Gamma W\|_\text{fro}^2.\]
We use the following definitions.
\[\mathcal{S}_{\mathcal{H}}^s = \{ W \in \mathcal{H}^s ~|~ \mathcal{G}(W)= I_s \}.\]
The usual way to solve KPCA is through SVD of \(G\) \(\Rightarrow\) slow with larger \(n\).
Key idea: Rewrite KPCA as a difference of convex functions. The new problem is
\[\inf_{W \in \mathcal{H}^s} ~ g(W) - f(\Gamma W),\]
with \(f = \frac{1}{2} \|\cdot\|_{\text{fro}}^2\), \(g = \iota_{\mathcal{S}_{\mathcal{H}}^s}(\cdot)\), and \(\iota_{\mathcal{C}}(\cdot)\) the indicator function for set \(\mathcal{C}\).
Two key advantages:
\[\inf_{W \in \mathcal{U}} ~ g(W) - f(\Gamma W).\]
admits the dual formulation
\[\inf_{H \in \mathcal{K}} ~ f^\star(H) - g^\star(\Gamma^\sharp H),\]
and strong duality holds.
Please refer to our paper for more experiments.
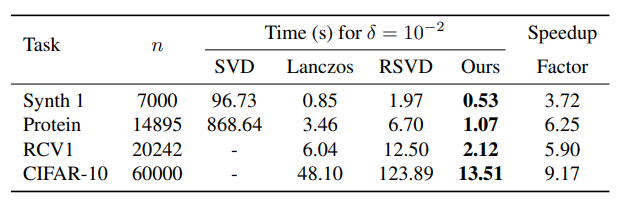
KPCA Training Time with higher tolerance. We compare to state-of-the-art KPCA solvers, including full SVD, Lanczos method, and Randomized SVD (RSVD). Speedup factor w.r.t. RSVD. We report training time in seconds on KPCA problems of different sizes. We show much faster training times..
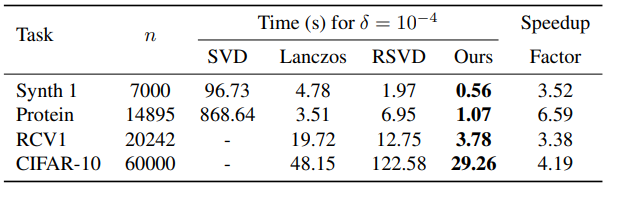
KPCA Training Time with lower tolerance. We compare to state-of-the-art KPCA solvers, including full SVD, Lanczos method, and Randomized SVD (RSVD). Speedup factor w.r.t. RSVD. We report training time in seconds on KPCA problems of different sizes. We show much faster training times..
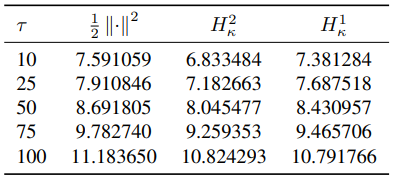
Robustness on contaminated Iris dataset. We report test reconstruction error (MSE) using the Huber losses after contaminating the Iris dataset validation set with Gaussian noise of different standard deviation \(\tau\). We evaluate performance by reconstruction error (MSE) in input space of non-contaminated test samples: higher MSE means that the learned subspace is influenced by the outliers, while lower MSE corresponds to more robust models..
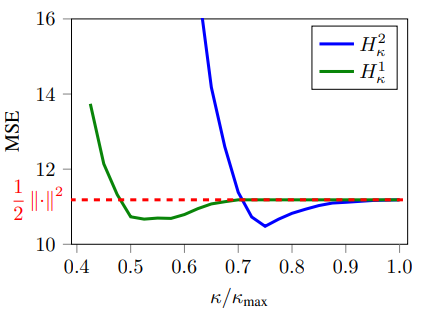
Effect of \(\kappa\) for the Huber losses. The Huber losses (blue and green lines) can be distinctively more robust to outliers than the square loss (red dashed line). When \(\kappa\) becomes closer to \(\kappa_\text{max}\), the robustness effect is void and the MSE converges to the one from the standard KPCA. With small \(\kappa\), the constraint on the dual variables is too strict, as the size of the projection ball becomes insufficient.
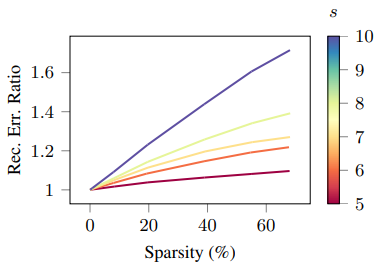
Reconstruction error for the \(\ell_\epsilon^\infty\) loss for multiple \(\epsilon\) and \(s\). The reconstruction error ratio is the ratio between the reconstruction error using the components learned with the \(\ell_\epsilon^\infty\) epsilon-insensitive loss and the reconstruction error from the square loss. Here, sparsity is in terms of percentage of zero entries of \(H\).
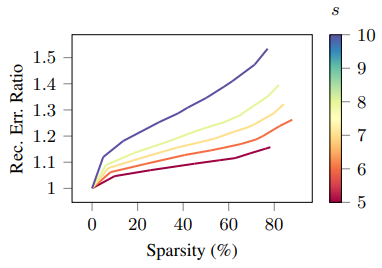
Reconstruction error for the \(\ell_\epsilon^2\) loss for multiple \(\epsilon\) and \(s\). The reconstruction error ratio is the ratio between the reconstruction error using the components learned with the \(\ell_\epsilon^2\) epsilon-insensitive loss and the reconstruction error from the square loss. Here, sparsity is in terms of percentage of zero rows in \(H\).
@InProceedings{tonin2023,
title = {Extending Kernel {PCA} through Dualization: Sparsity, Robustness and Fast Algorithms},
author = {Tonin, Francesco and Lambert, Alex and Patrinos, Panagiotis and Suykens, Johan},
booktitle = {The 40th International Conference on Machine Learning},
year = {2023},
organization= {PMLR}
}
This work is jointly supported by EU: The research leading to these results has received funding from the European Research Council under the European Union's Horizon 2020 research and innovation program / ERC Advanced Grant E-DUALITY (787960). This paper reflects only the authors' views and the Union is not liable for any use that may be made of the contained information. Research Council KU Leuven: Optimization frameworks for deep kernel machines C14/18/068 Flemish Government: FWO: projects: GOA4917N (Deep Restricted Kernel Machines: Methods and Foundations), PhD/Postdoc grant This research received funding from the Flemish Government (AI Research Program). EU H2020 ICT-48 Network TAILOR (Foundations of Trustworthy AI - Integrating Reasoning, Learning and Optimization) Leuven.AI Institute
© This webpage was in part inspired from this template.